 Smart Pointer TimingsSmart Pointer Timings
Smart Pointer TimingsSmart Pointer TimingsIn late January 2000, Mark Borgerding put forward a suggestion to boost for a new design of smart pointer whereby an intrusive doubly linked list is used to join together all instances of smart pointers sharing a given raw pointer. This allowed avoidance of the costly heap allocation of a reference count that occurred in the initial construction of the then current version of boost::shared_ptr. Of course, nothing is for free and the benefit here was gained at the expense of increased size and more costly copy operations. A debate ensued on the boost mailing list and the tests which this page describes were performed to provide a guide for current and future investigations into smart pointer implementation strategies.
Thanks are due to Dave Abrahams, Gavin Collings, Greg Colvin and Beman Dawes for test code and trial implementations, the final version of which can be found in .zip format here.
Two tests were run: the first aimed to obtain timings for two basic individual operations:
The second attempted to gain more insight into normal usage by timing the fill and sort algorithms for vectors and lists filled with the various smart pointers.
Five smart pointer implementation strategies were tested:
on two compilers:
Additionally, generated pointer sizes (taking into account struct alignment) were compared, as were generated code sizes for MSVC mainly by manual inspection of generated assembly code - a necessity due to function inlining.
All tests were run on a PII-200 running Windows NT version 4.0
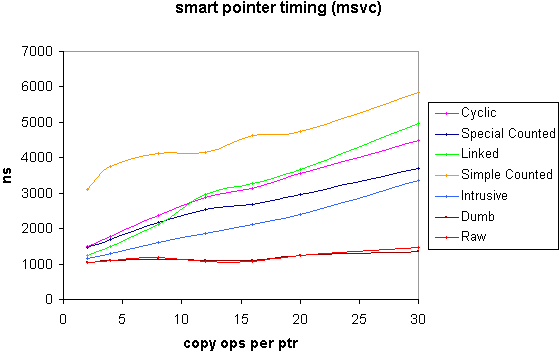
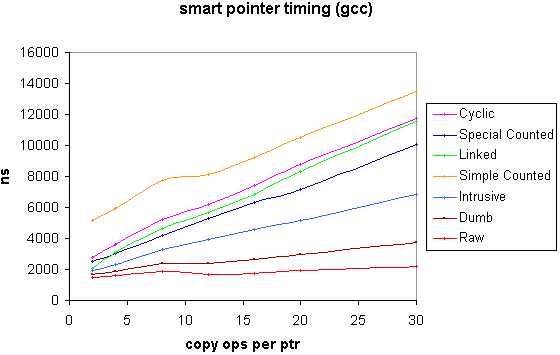
The following graphs show the overall time in nanoseconds to acquire a pointer (default construction) perform n amortized copy operations on it and finally release it. The initial allocation time for the contained pointer is not included, although the time for it's deallocation is. The contained pointer pointed to a trivial class, but for the inclusion of an intrusive reference count for the benefit of the intrusive counted shared pointer. A dumb pointer (i.e. a smart pointer that simply acquires and releases its contained pointer with no extra overhead) and a raw pointer were also included for comparison.
 |
||
 |
||
Fitting straight lines to the above plots gives the following figures for initialization and amortized copy operation for the two compilers (times in nanoseconds, errors at two standard deviations) : -
|
initialization
|
copy operation | |
|---|---|---|
|
simple counted
|
3000 +/- 170 | 104 +/- 31 |
|
special counted
|
1330 +/- 50 | 85 +/- 9 |
|
intrusive
|
1000 +/- 20 | 71 +/- 3 |
| linked | 970 +/- 60 | 136 +/- 10 |
| cyclic | 1290 +/- 70 | 112 +/- 12 |
| dumb | 1020 +/- 20 | 10 +/- 4 |
|
raw
|
1038 +/- 30 | 10 +/- 5 |
|
initialization
|
copy operation | |
|---|---|---|
|
simple counted
|
4620 +/- 150 | 301 +/- 28 |
|
special counted
|
1990 +/- 40 | 264 +/- 7 |
|
intrusive
|
1590 +/- 70 | 181 +/- 12 |
| linked | 1470 +/- 140 | 345 +/- 26 |
| cyclic | 2180 +/- 100 | 330 +/- 18 |
| dumb | 1590 +/- 70 | 74 +/- 12 |
|
raw
|
1430 +/- 60 | 27 +/- 11 |
Note that the above times include a certain amount of loop overhead etc. for each operation. An estimate of the pure smart pointer operation time 'overhead' can be obtained by subtracting the dumb or raw figure from the smart pointer time of interest.
The test involved iterating a loop which creates raw pointers. These were then shared among a varying number (set size) of smart pointers. A range of set sizes was used and then a line fitted to get a linear relation with number of initializations and copy-operations. A spreadsheet was used for the line fit, and to produce the performance graphs above.
To gain some insight in to operation within real life programs, this test was devised. Smart pointers were used to fill standard containers which were then sorted.
In this case, the contained pointer pointed to a class which initializes a private data member to a random value in its default constructor. This value is used subsequently for the sort comparison test. The class also contains an intrusive reference count for the benefit of the intrusive counted pointer.
All times are in seconds for 300,000 contained pointers.
| vector | list | |||
|---|---|---|---|---|
|
fill
|
sort | fill | sort | |
|
simple counted
|
46.54 | 2.44 | 47.09 | 3.22 |
|
special counted
|
14.02 | 2.83 | 7.28 | 3.21 |
|
intrusive
|
12.15 | 1.91 | 7.99 | 3.08 |
| linked | 12.46 | 2.32 | 8.14 | 3.27 |
| cyclic | 22.60 | 3.19 | 1.63 | 3.18 |
|
raw
|
11.81 | 0.24 | 27.51 | 0.77 |
| vector | list | |||
|---|---|---|---|---|
|
fill
|
sort | fill | sort | |
|
simple counted
|
1.83 | 2.37 | 1.86 | 4.85 |
|
special counted
|
1.04 | 2.35 | 1.38 | 4.58 |
|
intrusive
|
1.04 | 1.84 | 1.16 | 4.29 |
| linked | 1.08 | 2.00 | 1.21 | 4.33 |
| cyclic | 1.38 | 2.84 | 1.47 | 4.73 |
|
raw
|
0.67 | 0.28 | 1.24 | 1.81 |
The following code sizes were determined by inspection of generated code for MSVC only. Sizes are given in the form N / M / I where:
|
ptr()
|
ptr(p) | ptr(ptr) | op=() |
~ptr()
|
|
|---|---|---|---|---|---|
|
simple counted
|
38/110/O | 38/110/O | 9/23/I | 22/57/I | 17/40/I |
|
special counted
|
50/141/O | 50/141/O | 9/23/I | 23/64/I | 13/38/I |
|
intrusive
|
1/2/I | 3/6/I | 3/6/I | 6/11/I | 6/11/I |
|
linked
|
5/19/I | 5/15/I | 10/30/I | 27/59/I | 14/38/I |
During the code inspection, a couple of minor points were noticed: -
The following smart pointer sizes were obtained in bytes
|
MSVC
|
GCC
|
|
|---|---|---|
|
simple counted
|
8
|
8
|
|
special counted
|
8
|
12
|
|
intrusive
|
4
|
4
|
|
linked
|
12
|
12
|
|
cyclic
|
8
|
8
|
The timing results mainly speak for themselves: clearly an intrusive pointer outperforms all others and a simple heap based counted pointer has poor performance relative to other implementations. The selection of an optimal non-intrusive smart pointer implementation is more application dependent, however. Where small numbers of copies are expected, it is likely that the linked implementation will be favoured. Conversely, for larger numbers of copies a counted pointer with some type of special purpose allocator looks like a win. Other factors to bear in mind are: -
$Date$
© Copyright Gavin Collings 2000. Permission to copy, use, modify, sell and distribute this document is granted provided this copyright notice appears in all copies. This document is provided "as is" without express or implied warranty, and with no claim as to its suitability for any purpose.